
您身边的网站建设专家
日期: 2022-09-21 04:31:27 浏览数:4

上往建站提供服务器空间服务商,百度快照排名,网站托管,百度推广运营,致力于设计外包服务与源代码定制开发,360推广,搜狗推广,增加网站的能见度及访问量提升网络营销的效果,主营:网站公司,百度推广公司电话,官网搭建服务,网站服务企业排名,服务器空间,英文域名等业务,专业团队服务,效果好。
瓦房店淘宝装修/瓦房店京东店铺设计/瓦房店拼多多网店装修公司/瓦房店企业网店开通申请-网店装修设计

Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
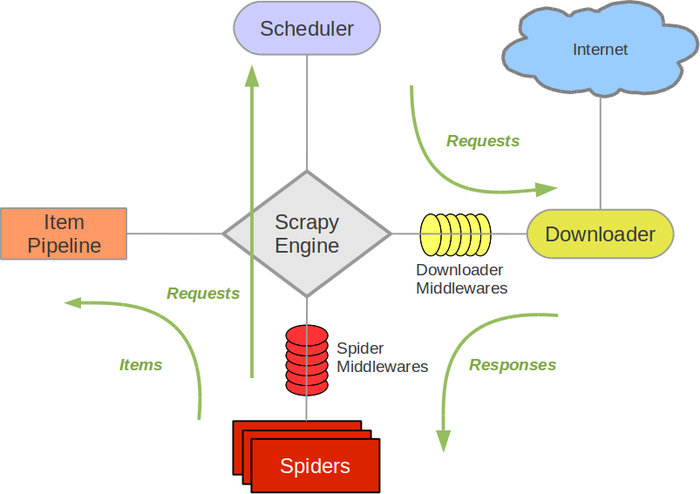
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
代码写好,程序开始运行...
1 引擎:Hi!Spider, 你要处理哪一个网站?
2 Spider:老大要我处理xxxx.com。
3 引擎:你把第一个需要处理的URL给我吧。
4 Spider:给你,第一个URL是xxxxxxx.com。
5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14 管道调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
安装
Windows 安装方式
升级 pip 版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
Ubuntu 安装方式
安装非 Python 的依赖:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-de
瓦房店淘宝装修/瓦房店京东店铺设计/瓦房店拼多多网店装修公司/瓦房店企业网店开通申请-网店装修设计
上往建站提供搭建网站,域名注册,官网备案服务,网店详情页设计,企业网店,专业网络店铺管理运营全托管公司咨询电话,服务器空间,微信公众号托管,网页美工排版,致力于域名申请,竞价托管,软文推广,全网营销,提供标准级专业技术保障,了却后顾之忧,主营:虚拟主机,网站推广,百度竞价托管,网站建设,上网建站推广服务,网络公司有哪些等业务,专业团队服务,效果好。
服务热线:400-111-6878 手机微信同号:18118153152(各城市商务人员可上门服务)
